
[데이크루] 심리 성향 예측 AI 경진대회 Stage 1
Stage 1
<Stage 1. 내용>
프로젝트 소개 및 데이터 이해 + 참여 코드
<학습 목표="">
프로젝트를 이해하고 데이터를 불러올 수 있다
<목차>
1
2
3
4
5
6
7
1. 인트로
2. 프로젝트 배경 및 이해
3. 데이터
3.1 데이터 불러오기
3.2 데이터 살펴보기
3.3 데이터 제출하기
1. 인트로

### 민주주의의 🌺과 같은 ‘투표’ 투표는 선택이 아니라 필수입니다!!
여러분의 소중한 한표를 결정짖는 다양한 원인들
그 비밀을 😶🌫️지금부터 같이 파헤쳐 봅시다!!
2. 프로젝트 배경
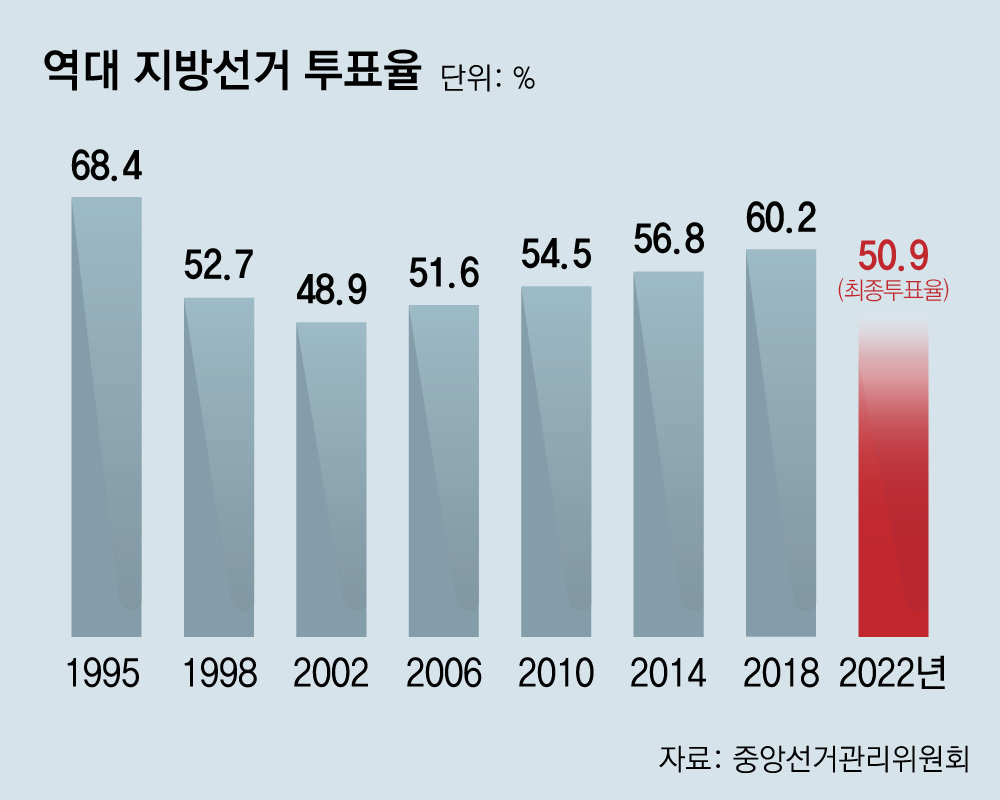
# '저조한 투표율'
민주주의 국가라면 하지않을 수 없는 걱정중 하나입니다.
만약 투표율에 영향을 미치는 심리를 파악하고 이를 분석할 수 있다면 투표율 증가에 도움이 되지 않을까요?
최근들어 심리학의 범주가 넓어지게 되면서 다양한 조사방법들이 등장하게 되었습니다.
또한 이를 통해서 다양한 형태의 심리 유형 데이터를 획득할 수 있게 되었는데요
우리는 이를 통해서 국가 투표에 참여/비참여한 사람들의 심리를 분석해보려합니다!!
벌써부터 기대되신다고요??
그럼 시작합니다!!🏃♂️
3. 데이터
3.1 데이터 불러오기
데이터 분석을 하기전에 먼저 우리가 갖고 있는 데이터를 살펴봅시다!!
요리사가 요리를 하기전에 재료를 살펴보듯이 말이죠!
우리가 갖고 있는 데이터는 총 3개의 csv파일입니다
1
2
3
4
├-- train.csv (데이터 학습을 위한 train data)
├-- test.csv (학습 모델을 평가하기 위한 test data)
├-- sample_submission (평가한 test data의 예측값을 기록하기 위한 답지)
파이썬에서 위 데이터를 불러오기 위해서는 pandas 라이브러리를 활용하면 됩니다.
3.1.1 Import
1
2
3
4
5
# 라이브러리 import 하기
import pandas as pd
#sample_submission.csv 파일 불러오기
submission = pd.read_csv('sample_submission.csv')
pandas는 앞으로 우리가 가장 많이 사용하는 라이브러리로
주로 csv 파일로 되어 있는 데이터를 가지고 올 때 사용되지만, 다른 파일도 불러오기 및 저장이 가능합니다.
(주의 : 현재 csv경로는 주피터 노트북파일이 있는 위치에 있어야합니다. 만약 다른곳에 있는 경우 pd.read_csv(파일경로)를 지정해주세요!!)
Q1.
그럼 위의 방법을 활용해서 train data와 test data를 불러와 볼까요??
pandas를 import해서 pd로 약칭을 지정해주고 이를 활용해
아래의 변수명으로 train.csv와 test_x.csv를 직접 불러와 주세요
trian.csv - 변수명 : train_df
test_x.csv - 변수명 : test_x
Hint
-
import한 라이브러리 뒤에as를 붙여주면 라이브러리의 별명을 만들어 줄 수 있습니다. -
read_csv메소드는pandas안에 위치한 메소드로pd.read_csv의 방식으로 사용할 수 있습니다.
Solution
1
2
3
4
5
# 데이터 파일 읽기
import pandas as pd
train_df = pd.read_csv('train.csv')
test_x = pd.read_csv('test_x.csv')
pandas는 DataFrame이라는 클래스의 객체로 데이터를 읽어 드리며
DataFrame의 약칭으로 df라고 많이 사용합니다. 그래서
train 데이터 변수명은 train_df인데 test 데이터가 test_x인 이유는
train_df에는 입력 데이터 x와 정답 데이터 y가 한꺼번에 담겨 있지만, label이 포함되어 있지 않기 때문에 입력 데이터 x를 의미하기 위해 test_x라고 했습니다.
3.2 데이터 살펴보기
3.2.1 head
그럼 이렇게 가져온 데이터를 한번 살펴볼까요?
1
train_df
| index | QaA | QaE | QbA | QbE | QcA | QcE | QdA | QdE | QeA | ... | wr_04 | wr_05 | wr_06 | wr_07 | wr_08 | wr_09 | wr_10 | wr_11 | wr_12 | wr_13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3.0 | 363 | 4.0 | 1370 | 5.0 | 997 | 1.0 | 1024 | 2.0 | ... | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 5.0 | 647 | 5.0 | 1313 | 3.0 | 3387 | 5.0 | 2969 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 2 | 2 | 4.0 | 1623 | 1.0 | 1480 | 1.0 | 1021 | 4.0 | 3374 | 5.0 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 3 | 3 | 3.0 | 504 | 3.0 | 2311 | 4.0 | 992 | 3.0 | 3245 | 1.0 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 |
| 4 | 4 | 1.0 | 927 | 1.0 | 707 | 5.0 | 556 | 2.0 | 1062 | 1.0 | ... | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 45527 | 45527 | 2.0 | 1050 | 5.0 | 619 | 4.0 | 328 | 1.0 | 285 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 45528 | 45528 | 2.0 | 581 | 3.0 | 1353 | 4.0 | 1164 | 1.0 | 798 | 3.0 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 45529 | 45529 | 4.0 | 593 | 1.0 | 857 | 1.0 | 1047 | 4.0 | 1515 | 5.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 45530 | 45530 | 1.0 | 747 | 3.0 | 1331 | 4.0 | 892 | 2.0 | 1281 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 45531 | 45531 | 3.0 | 496 | 5.0 | 1827 | 5.0 | 754 | 3.0 | 1117 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
45532 rows × 78 columns
jupyter에서는 이렇게 가져온 csv의 변수명을 입력해주면 DataFrame의 형태로 출력됩니다!!
그런데 우리가 가진 train data가 45532개인데 화면에 보이는것은 전체데이터의 부분이네요??
만약 모든 데이터를 출력시킨다면 출력되는 데이터가 화면창을 가득채울것입니다.
그러니까 자동으로 축약해서 보여주는것이죠
그렇다면 특정데이터를 보고 싶다면 어떻게 해야할까요?
1
2
# 데이터 미리보기
train_df.head()
| index | QaA | QaE | QbA | QbE | QcA | QcE | QdA | QdE | QeA | ... | wr_04 | wr_05 | wr_06 | wr_07 | wr_08 | wr_09 | wr_10 | wr_11 | wr_12 | wr_13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3.0 | 363 | 4.0 | 1370 | 5.0 | 997 | 1.0 | 1024 | 2.0 | ... | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 5.0 | 647 | 5.0 | 1313 | 3.0 | 3387 | 5.0 | 2969 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 2 | 2 | 4.0 | 1623 | 1.0 | 1480 | 1.0 | 1021 | 4.0 | 3374 | 5.0 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 3 | 3 | 3.0 | 504 | 3.0 | 2311 | 4.0 | 992 | 3.0 | 3245 | 1.0 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 |
| 4 | 4 | 1.0 | 927 | 1.0 | 707 | 5.0 | 556 | 2.0 | 1062 | 1.0 | ... | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
5 rows × 78 columns
먼저 head입니다.
DataFrame의 메소드head()를 통해 index가 작은 행을 미리 볼 수 있습니다.
(0부터 차례대로 보여주는 것입니다)
head()의 괄호 안에 들어가는 값에 따라서 0부터 원하는 만큼 볼 수 있습니다.
(default 값은 5입니다.)
Q2.
그럼 0부터 10개의 데이터를 한번 불러와 볼까요?
Hint
DataFrame의head()메소드를 활용한다head()괄호 안에 들어가는 수에 따라 보여지는 데이터가 달라진다
Solution
1
train_df.head(10)
| index | QaA | QaE | QbA | QbE | QcA | QcE | QdA | QdE | QeA | ... | wr_04 | wr_05 | wr_06 | wr_07 | wr_08 | wr_09 | wr_10 | wr_11 | wr_12 | wr_13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3.0 | 363 | 4.0 | 1370 | 5.0 | 997 | 1.0 | 1024 | 2.0 | ... | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 5.0 | 647 | 5.0 | 1313 | 3.0 | 3387 | 5.0 | 2969 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 2 | 2 | 4.0 | 1623 | 1.0 | 1480 | 1.0 | 1021 | 4.0 | 3374 | 5.0 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 3 | 3 | 3.0 | 504 | 3.0 | 2311 | 4.0 | 992 | 3.0 | 3245 | 1.0 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 |
| 4 | 4 | 1.0 | 927 | 1.0 | 707 | 5.0 | 556 | 2.0 | 1062 | 1.0 | ... | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| 5 | 5 | 2.0 | 834 | 1.0 | 1769 | 4.0 | 2105 | 1.0 | 1070 | 5.0 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 6 | 6 | 1.0 | 1382 | 1.0 | 1473 | 5.0 | 1479 | 4.0 | 2403 | 1.0 | ... | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 7 | 7 | 1.0 | 384 | 1.0 | 908 | 5.0 | 870 | 1.0 | 1059 | 1.0 | ... | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 8 | 8 | 5.0 | 795 | 2.0 | 3469 | 4.0 | 1693 | 3.0 | 1991 | 4.0 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 |
| 9 | 9 | 2.0 | 1668 | 1.0 | 866 | 1.0 | 895 | 1.0 | 1308 | 2.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
10 rows × 78 columns
0~9까지의 데이터가 우리 눈앞에 나타났습니다.
10을 넣었는데 왜 9까지의 데이터만 보여지냐고요?
Python의 index는 대부분 0부터 시작합니다. 따라서 우리가 원하는건 10개의 데이터였으니 0~9까지가 10개라고 할 수 있습니다!!
3.2.2 tail
지금까지 앞에 위치한 데이터를 살펴봤습니다.
그렇다면 뒤에 위치한 데이는 어떻게 살펴볼 수 있을까요?
방법은 비슷합니다. 바로 tail()메소드를 head()대신에 사용하면 됩니다.
1
train_df.tail()
| index | QaA | QaE | QbA | QbE | QcA | QcE | QdA | QdE | QeA | ... | wr_04 | wr_05 | wr_06 | wr_07 | wr_08 | wr_09 | wr_10 | wr_11 | wr_12 | wr_13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 45527 | 45527 | 2.0 | 1050 | 5.0 | 619 | 4.0 | 328 | 1.0 | 285 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 45528 | 45528 | 2.0 | 581 | 3.0 | 1353 | 4.0 | 1164 | 1.0 | 798 | 3.0 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 45529 | 45529 | 4.0 | 593 | 1.0 | 857 | 1.0 | 1047 | 4.0 | 1515 | 5.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 45530 | 45530 | 1.0 | 747 | 3.0 | 1331 | 4.0 | 892 | 2.0 | 1281 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 45531 | 45531 | 3.0 | 496 | 5.0 | 1827 | 5.0 | 754 | 3.0 | 1117 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
5 rows × 78 columns
그럼 마지막에 위차한 데이터 부터 순서대로 5개의 데이터가 표시되게 됩니다.
tail()도 head()와 마찬가지로 괄호안에 숫자를 통해서 데이터의 수를 조정할 수 있습니다. (default 값은 동일하게 5입니다!!)
Q3.
그럼 이번에는 마지막을 기준으로 15개의 데이터를 가져와 볼까요?
Hint
DataFrame의tail()메소드를 활용한다tail()괄호 안에 들어가는 수에 따라 보여지는 데이터가 달라진다
Solution
1
train_df.tail(15)
| index | QaA | QaE | QbA | QbE | QcA | QcE | QdA | QdE | QeA | ... | wr_04 | wr_05 | wr_06 | wr_07 | wr_08 | wr_09 | wr_10 | wr_11 | wr_12 | wr_13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 45517 | 45517 | 1.0 | 439 | 5.0 | 747 | 5.0 | 738 | 1.0 | 600 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 45518 | 45518 | 1.0 | 476 | 5.0 | 2440 | 5.0 | 1545 | 1.0 | 1676 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| 45519 | 45519 | 2.0 | 941 | 1.0 | 12535 | 1.0 | 1261 | 2.0 | 2278 | 5.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 45520 | 45520 | 4.0 | 728 | 1.0 | 1669 | 4.0 | 1397 | 3.0 | 714 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| 45521 | 45521 | 2.0 | 496 | 3.0 | 1359 | 4.0 | 744 | 2.0 | 1048 | 2.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 45522 | 45522 | 1.0 | 1014 | 2.0 | 6022 | 2.0 | 3351 | 4.0 | 3788 | 1.0 | ... | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 45523 | 45523 | 1.0 | 365 | 4.0 | 1130 | 5.0 | 486 | 1.0 | 572 | 2.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 45524 | 45524 | 2.0 | 254 | 4.0 | 839 | 2.0 | 557 | 2.0 | 768 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 |
| 45525 | 45525 | 1.0 | 549 | 4.0 | 2383 | 5.0 | 1222 | 1.0 | 1672 | 2.0 | ... | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 45526 | 45526 | 4.0 | 454 | 5.0 | 1007 | 4.0 | 758 | 2.0 | 1117 | 3.0 | ... | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 45527 | 45527 | 2.0 | 1050 | 5.0 | 619 | 4.0 | 328 | 1.0 | 285 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 45528 | 45528 | 2.0 | 581 | 3.0 | 1353 | 4.0 | 1164 | 1.0 | 798 | 3.0 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 45529 | 45529 | 4.0 | 593 | 1.0 | 857 | 1.0 | 1047 | 4.0 | 1515 | 5.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
| 45530 | 45530 | 1.0 | 747 | 3.0 | 1331 | 4.0 | 892 | 2.0 | 1281 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 1 |
| 45531 | 45531 | 3.0 | 496 | 5.0 | 1827 | 5.0 | 754 | 3.0 | 1117 | 1.0 | ... | 1 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 1 | 1 |
15 rows × 78 columns
마지막을 기준으로 15개의 데이터를 가져왔습니다!!
그런데 괄호안에 수를 계속 늘리면 모든 데이터를 표시할 수 있을까요??
그건 불가능합니다.
화면에 표시될 수 있는 수가 정해져있기 때문에 많을 수를 넣으면 가장 처음에 본 표처럼 축약되서 나타나게 됩니다!!
직접해보세요!!
3.3 데이터 제출하기
그럼 이제 데이터를 한번 제출해볼까요??
DAICON에 데이터를 제출하기 위해서는 csv형태의 데이터를 제출해야합니다.
우리에게는 예시 데이터로 sample_submission.csv가 있습니다.
import 파트에서 submission라는 변수 명으로 지정해 두었습니다.
한번 살펴볼까요??
1
submission
| index | voted | |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 3 | 0 |
| 4 | 4 | 0 |
| ... | ... | ... |
| 11378 | 11378 | 0 |
| 11379 | 11379 | 0 |
| 11380 | 11380 | 0 |
| 11381 | 11381 | 0 |
| 11382 | 11382 | 0 |
11383 rows × 2 columns
index와 voted라는 열로 구성되어있습니다. (‘행’과 ‘열’ 개념은 Stage.2 와 3에서 더 자세히 다루겠습니다)
그럼 이 변수로 지정되어있는 DataFrame을 어떻게 csv 파일로 저장할 수 있을까요?
to.csv() 메소드를 활용하면 됩니다.
1
2
# 저장하기
submission.to_csv('./submit.csv', index=False)
to.csv메소드에 저장할 경로와 파일 형식을 지정해주면 저장이 됩니다,
또한 index를 True로 지정해주면 index가 생성되고 False로 저장하면 index는 저장되지 않습니다.
Q4.
이번 Stage의 마지막 실습입니다!!
train_df을 현재 Jupyter 파일이 위치하는 경로에 train_df_copy.csv으로 저장해주세요
또한 index도 저장되게 설정해 주세요
Hint
DataFrame의to.csv()메소드를 활용한다to.csv()괄호 안에 경로를 지정할 수 있고index라는 파라미터를 통해서 index를 조절할 수 있다
Solution
1
train_df.to_csv('train_df_copy.csv', index=True)
4. 정리
이번 Stage. 1에서는 간단한 프로젝트 설명과
데이터를 불러오는 방법,
그리고 불러온 데이터를 간단하게 살펴보고 csv파일로 저장하는 방법을 살펴보았습니다.
아래에 다시한번 간단하게 정리해두었으니 다시한번 살펴보고 복습해보세요!!
import:python의 라이브러리를 불러온다
pd.read_csv(): csv파일을 불러온다
DataFrame.head(): 데이터프레임에서 앞에 위치한 데이터를 출력해주며 괄호안의 값을 조정하여 출력되는 데이터의 수를 조절할 수있다.
DataFrame.tail(): 데이터프레임에서 뒤에 위치한 데이터를 출력해주며 괄호안의 값을 조정하여 출력되는 데이터의 수를 조절할 수있다.
다음 Stage 2.에서는 우리가 갖고있는 데이터로 가장 기본적인 모델을 만들어보고 모델에 영향을 미친 주요 변수들을 살펴보도록 하겠습니다!!